The pursuit of performance is something that interests me as a developer, so as a learning exercise I decided to experiment and consolidate my knowledge about multi-threading. Nowadays it’s becoming even more important since our CPUs get more and more cores. Modern game engines and applications use multiple CPU cores to stay fast and responsive.
Index
- Part 1: Exploring Multi-Threading in C++
- Part 2: Exploring Multi-Threading in C++ Cont.
- Part 3: Exploring Multi-Threading in C++: Loading Textures
- Part 4: Exploring Multi-Threading in C++: Parallelizing Ray Tracing
Setup and Baseline Result
As a test case, I decided to create a series of tasks, ones small and other big, to simulate different workload types. As an easy test case, I grabbed a method to calculate Pi, and run that method multiple times, depending on how heavy I want the workload to be.
double CalcPi(int n)
{
double sum = 0.0;
int sign = 1;
for (int i = 0; i < n; ++i)
{
sum += sign / (2.0 * i + 1.0);
sign *= -1;
}
return 4.0 * sum;
}
Now I create a couple of different Jobs running CalcPi and add them into a vector or a queue ( depending on the test I’m running ). My CalcPiJob class looks something like this.
class CalcPiJob
{
public:
CalcPiJob(int iterations)
: m_iterations(iterations)
{ }
void DoWork()
{
float p = 0.0f;
for (int i = 0; i < m_iterations; ++i) {
p += CalcPi(m_iterations);
}
p /= m_iterations;
std::this_thread::sleep_for(std::chrono::milliseconds(Settings::ThreadPause));
}
private:
int m_iterations;
};
Creating a series of different workload types looks something like:
std::queue<CalcPiJob*> GetJobsQ()
{
std::queue<CalcPiJob*> jobQ;
for (int i = 0; i < Settings::JobCountHigh; ++i)
{
jobQ.emplace(new CalcPiJob(Settings::IterationCountHigh));
}
for (int i = 0; i < Settings::JobCountMedium; ++i)
{
jobQ.emplace(new CalcPiJob(Settings::IterationCountMedium));
}
for (int i = 0; i < Settings::JobCountLow; ++i)
{
jobQ.emplace(new CalcPiJob(Settings::IterationCountLow));
}
return jobQ;
}
std::vector<CalcPiJob*> GetJobVector()
{
std::vector<CalcPiJob*> jobs;
for (int i = 0; i < Settings::JobCountHigh; ++i)
{
jobs.push_back(new CalcPiJob(Settings::IterationCountHigh));
}
for (int i = 0; i < Settings::JobCountMedium; ++i)
{
jobs.push_back(new CalcPiJob(Settings::IterationCountMedium));
}
for (int i = 0; i < Settings::JobCountLow; ++i)
{
jobs.push_back(new CalcPiJob(Settings::IterationCountLow));
}
return jobs;
}
I have also defined a couple of constants to help out.
struct Settings
{
enum class Priority : int {
Low = 0,
Medium,
High
};
static const int JobCountLow = 120;
static const int JobCountMedium = 60;
static const int JobCountHigh = 25;
static const int ThreadPause = 100;
static const int IterationCountLow = 5000;
static const int IterationCountMedium = 10000;
static const int IterationCountHigh = 20000;
static const int PrecisionHigh = 100;
static const int PrecisionMedium = 100;
static const int PrecisionLow = 100;
};
Now for baseline, I go through all Jobs and execute DoWork sequentially.
void RunSequential()
{
std::queue<CalcPiJob*> jobQ = GetJobsQ();
while (!jobQ.empty())
{
CalcPiJob* job = jobQ.front();
jobQ.pop();
job->DoWork();
delete job;
}
}
I’m running all my tests on a i7 4770K, that has 4 cores and 8 threads. All timings where taken from a release build, and all profile images from debug builds ( for illustration of workload purposes ).
Sequential run time: 20692 ms

First Worker Thread
Let the interesting part begin. As an easy step towards a multi-threading application, I’m going to create only one thread, to share the workload with the main thread.
This already brings a few new concepts to be aware of such as sharing data across multiple threads. We protect our data access with a std::mutex, and lock it with std::scoped_lock ( introduced in C++17. Use similar std::lock_guard if your compiler doesn’t support it ).
You’ll need a few includes first.
// you should already have these.
#include <vector>
#include <queue>
#include <thread> // thread support
#include <mutex> // mutex support
#include <atomic> // atomic variables
#include <future> // later on for std::async
CalcPiJob* GetAndPopJob(std::queue<CalcPiJob*>& jobQ, std::mutex& mutex)
{
std::scoped_lock<std::mutex> lock(mutex);
if (!jobQ.empty())
{
CalcPiJob* job = jobQ.front();
jobQ.pop();
return job;
}
return nullptr;
}
GetAndPopJob does exactly what is says, it will get a job if one exists and pop it from the queue. empty(), front() and pop() are protected inside this method with the use of the std::scoped_lock.
void ExecuteJobsQ(std::atomic<bool>& hasWork,
std::queue<CalcPiJob*>& jobQ,
std::mutex& mutex)
{
while (hasWork)
{
CalcPiJob* currentJob = GetAndPopJob(jobQ, mutex);
if (currentJob)
{
currentJob->DoWork();
delete currentJob;
}
else
{
hasWork = false;
}
}
}
ExecuteJobsQ will run in the main thread and the worker thread. It gets a job, execute it, and continue until there is no more work to do.
// global mutex for read/write access to Job Queue
static std::mutex g_mutexJobQ;
void RunOneThread()
{
std::queue<CalcPiJob*> jobQ = GetJobsQ();
std::atomic<bool> jobsPending = true;
// Starting new thread
std::thread t([&]() {
ExecuteJobsQ(jobsPending, jobQ, g_mutexJobQ);
});
// main thread, also does the same.
ExecuteJobsQ(jobsPending, jobQ, g_mutexJobQ);
t.join();
}
One worker thread run time: 10396 ms

The image above show the execution of the jobs, the larger ones first, then the medium sized ones and lastly the smaller ones. This was the order at which the tasks where added into the queue.
More Worker Threads
Now this is nice, so lets add more threads! How many? Well, I know my CPU has 8 thread, but nothing guarantees they will only run for my program tho. Operating system time slice program execution across multiple cores/threads, so even if you create more threads than your max CPU threads, there’s no “problem” because the operating system will switch execution time for them on its own.
C++ provides us a way of determining how many concurrent threads our system supports, so lets just use that: std::thread::hardware_concurrency()
void RunThreaded()
{
// -1 to make space for main thread
int nThreads = std::thread::hardware_concurrency() - 1;
std::vector<std::thread> threads;
std::queue<CalcPiJob*> jobQ = GetJobsQ();
std::atomic<bool> hasJobsLeft = true;
for (int i = 0; i < nThreads; ++i)
{
std::thread t([&]() {
ExecuteJobsQ(hasJobsLeft, jobQ, g_mutexJobQ);
});
threads.push_back(std::move(t));
}
// main thread
ExecuteJobsQ(hasJobsLeft, jobQ, g_mutexJobQ);
for (int i = 0; i < nThreads; ++i)
{
threads[i].join();
}
}
Run time with 8 threads: 2625 ms.

Now this is a nicer view. 7 worker threads working with the main thread to process all jobs. Again, first we see the bigger jobs, then medium, then smaller ones being processed. This is being processed in the order they were added.
Async Tasks
When spawning tasks with std::async, we don’t manually create threads, they are spawned from a thread pool.
void RunJobsOnAsync()
{
std::vector<CalcPiJob*> jobs = GetJobVector();
std::vector<std::future<void>> futures;
for (int i = 0; i < jobs.size(); ++i)
{
auto j = std::async([&jobs, i]() {
jobs[i]->DoWork();
});
futures.push_back(std::move(j));
}
// Wait for Jobs to finish, .get() is a blocking operation.
for (int i = 0; i < futures.size(); ++i)
{
futures[i].get();
}
for (int i = 0; i < jobs.size(); ++i)
{
delete jobs[i];
}
}
Run time: 2220 ms
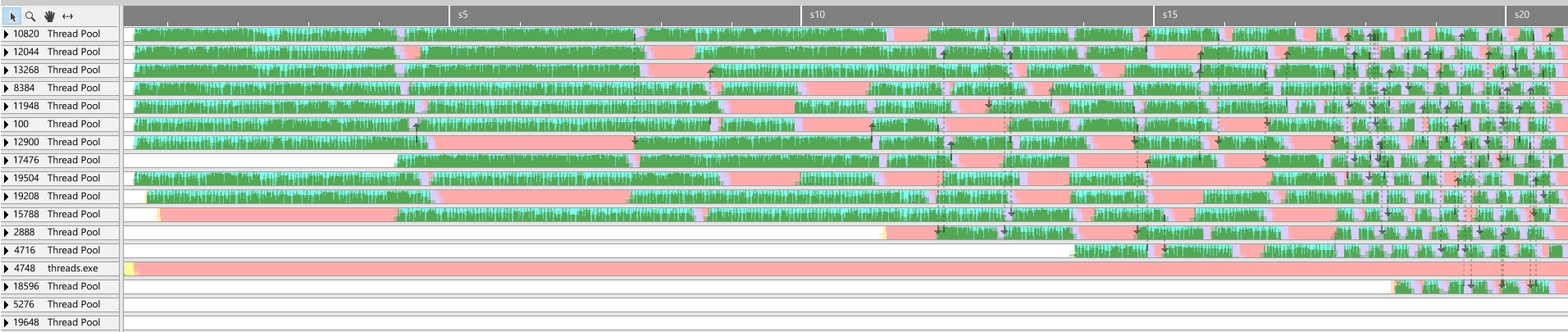
Overview
This time table only serves as an overview for this particular case. Of course, in real applications, results vary.
| Test Run | Time (ms) | Improvement |
|---|---|---|
| Sequential | 20692 | 1.x |
| One Thread | 10396 | 1.99x |
| Threaded | 2625 | 7.88x |
| Async Tasks * | 2220 | 9.3x |
The sample codes are my exploration of this specific case and by no means is free of bugs. But it is interesting to see how the code would run across multiple thread, how to synchronize and make the most of my system.
All screenshots are taken with the debug version of the program, so we could clearly see the workload in the profiler. For that I used Superluminal Profiler. I found out that it is an amazing, lightweight profiler. You can also use Intel’s VTune for free.
Continue Reading
- Part 1: Exploring Multi-Threading in C++
- Part 2: Exploring Multi-Threading in C++ Cont.
- Part 3: Exploring Multi-Threading in C++: Loading Textures
- Part 4: Exploring Multi-Threading in C++: Parallelizing Ray Tracing
Note
* I’ve revisited Async Tasks to make sure all tasks where fully complete before exiting the function call. I managed to get worse performance than the baseline test. Upon inspection with vTune, I found out, that it doesn’t launch new threads. This change happens from Debug/Release builds. I believe there is some optimization that makes it be that fast, even more so because most of the time spent on each jobs is an artificial wait. In any case, read those values with a grain of salt. Do your own tests and make your own conclusions.