Index
- Part 1: Exploring Multi-Threading in C++
- Part 2: Exploring Multi-Threading in C++ Cont.
- Part 3: Exploring Multi-Threading in C++: Loading Textures
- Part 4: Exploring Multi-Threading in C++: Parallelizing Ray Tracing
Setup
I’m going to use Ray Tracing in one weekend as a basis for this article. I’ve implemented a ray tracer based on these books by Peter Shirley, but the books have since been updated and moved into a new repository. So this is a nice and clean entry point if you want to follow along.
Single Threaded
You can fork my version of RayTracingOneWeekend, I’ve added a CMakeFile and edited the project so it writes the resulting image into a file. I made a baseline branch for the default result for creating a 1200x800 image with 10 samples per pixel.

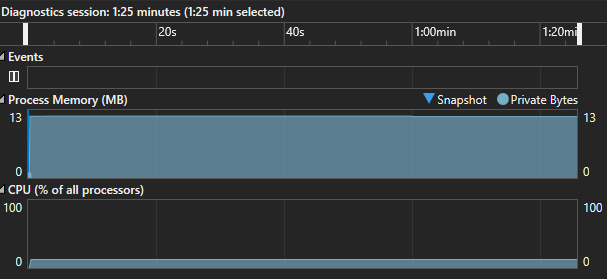
On my CPU this takes around 88 seconds, and overall uses only 13Mb of memory during runtime.
Naive Jobification
In order to have an idea of different approaches to make this run faster, I decided to start by using std::async, and create one job per pixel. I assumed from the beginning that this would bring “some” speed gains, but some caveats.
Once again, I’ve made a new branch for the Jobs version of the Ray Tracer, feel free to download that and experiment with it. The main changes include creating a std::async job for each pixel, saving the std::future<ResultJob> in a vector, and using a std::condition_variable to wait until all jobs are complete.
std::mutex mutex;
std::condition_variable cvResults;
std::vector<std::future<RayResult>> m_futures;
for (int j = 0; j < ny; ++j) {
for (int i = 0; i < nx; ++i) {
auto future = std::async(std::launch::async | std::launch::deferred,
[&cam, &world, &ns, i, j, nx, ny, &cvResults]() -> RayResult {
const unsigned int index = j * nx + i;
vec3 col(0, 0, 0);
for (int s = 0; s < ns; ++s) {
float u = float(i + random_double()) / float(nx);
float v = float(j + random_double()) / float(ny);
ray r = cam.get_ray(u, v);
col += color(r, world, 0);
}
col /= float(ns);
RayResult result;
result.index = index;
result.col = vec3(sqrt(col[0]), sqrt(col[1]), sqrt(col[2]));
return result;
});
{
std::lock_guard<std::mutex> lock(mutex);
m_futures.push_back(std::move(future));
}
}
}
This is what the main loop now looks like. RayResult is a simple struct containing the image index and resulting color value. After this, I wait for m_futures to be the same value as the number of pixels in the image, and then build the image before writing it to a file.
// launched jobs. need to build image.
// wait for number of jobs = pixel count
{
std::unique_lock<std::mutex> lock(mutex);
cvResults.wait(lock, [&m_futures, &pixelCount] {
return m_futures.size() == pixelCount;
});
}
// reconstruct image.
for (std::future<RayResult>& rr : m_futures)
{
RayResult result = rr.get();
image[result.index] = result.col;
}

The resulting image is the same. As expected this reduced execution time to around 23 seconds, 3.8x improvement. But not everything is looking good, on the contrary, we now started to use a lot more memory!
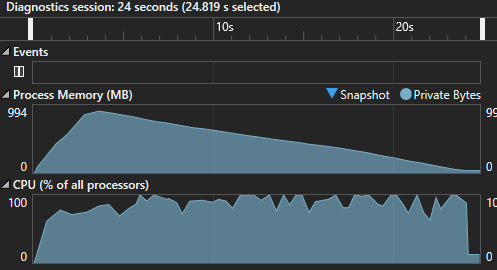
Now this took almost 1 Gb of memory while running, compared to the 13Mb for the single threaded version! CPU usage is almost 100% across all the execution, meaning most cores where used, but that memory usage is way too high. I think we can do better!
Threads and Blocks
The next implementation involves creating N-Threads, the number of threads my CPU can run concurrently, and splitting the image into N blocks of image rows. I’ll be using a std::condition_variable to determine if each thread has finished as well, and we’ll see if this improves our program.
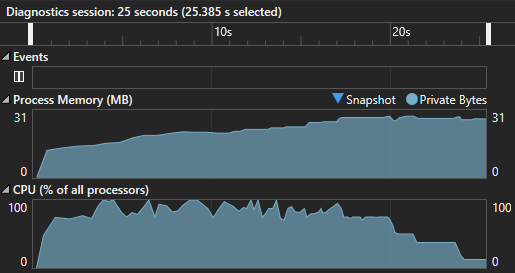
We do get around the same speed benefit and a small enough increase in memory consumption from the baseline test. std::async jobs still performs faster, but I suspect that is it because some of the blocks had less work to do than other, and therefor, finished first. This will make some of our CPU cores idle while the threads finish their blocks ( we can see that from the decrease CPU usage in the screenshot above ). The image is less computationally intensive in some areas than others, think about diffuse spheres versus refractive ones.
Now, I also think that if we used std::async, and split work equally in blocks, we would also reduce memory consumption and calculate the image slower. I think we need to find a nice balance between jobs sizes, obviously one job per pixel is too little and a too big block might cause idle time if the jobs is performed too fast ( assuming that thread doesn’t have another job to perform )
You can grab the source code on GitHub
Fine Tuning Job Sizes
If we have less jobs than CPU cores, some of them become idle and have no more jobs to take on. I’ve created new tests to try out different job sizes. You can check out the code for the image block version using threads and using std::async.
In both branches, you can edit nRowsPerJob to test different job sizes.
const int nThreads = std::thread::hardware_concurrency();
int nRowsPerJob = 10; // play with amount of rows for each job
int nJobs = ny / nRowsPerJob;
int leftOver = ny % nThreads;
I managed to get the same results on both methods. I no longer get a gigantic 1Gb memory usage with std::async, but now using a reasonable amount of pixels to generate, instead of one. There is no visible benefit in terms of performance from threads vs std::async that I could see. On both versions, with various block sizes, I had the same results: around 24 seconds per image and 30Mb of memory usage. By keeping the number of images rows per block low, more jobs will be created and this is ideal to split jobs evenly across CPU cores.
Take away
I set out to expand and consolidate my knowledge on multi threading paradigms and concepts using c++, using some older and some newer c++ features, and I had a lot of fun doing so.
I’m sure there’s lot of room for improvement and provably made lots of mistakes, if I did, let me know. In any case I hope you can take your own conclusions and maybe learn something too.